KerasとgensimでなんJスレタイ生成器を構築する(1回目)
最近リベンジしました
初めて買ったGPU(GeForce GTX 1050 Ti)を試用するために、 Kerasとgensimを使ってなんJスレタイ生成器をつくってみました。
生成サンプルは以下のとおりです。似たようなものが多いですが、なんJ感がでていて良い感じなものができました。
# 「【悲報」から始まるスレタイ _start_ 【 悲報 】 なんJ 民 とんでも ない こと を し て しまう _end_ _start_ 【 悲報 】 なんJ 民 さん ガチ で やっ て い た _end_ _start_ 【 悲報 】 なんJ 民 さん とんでも ない こと を し て しまう _end_ _start_ 【 悲報 】 なんJ 民 とんでも ない 事 を し て しまう _end_ _start_ 【 悲報 】 なんJ 民 に 自信 ニキ 来 て くれ や _end_ # 「ワイ」から始まるスレタイ _start_ ワイ 陰 キャ だ けど 駅 の トイレ で 泣い てる _end_ _start_ ワイ ( _num_ ) だ けど 駅 の トイレ で 泣い てる _end_ _start_ ワイ しか 見 て ない こと を し て しまう WARATOKEN _end_ _start_ ワイ しか 見 て ない こと に なっ て しまう WARATOKEN _end_ _start_ ワイ 「 お前 ら が 好き な ん です か ?」 _end_ # 「こんな」から始まるスレタイ _start_ こんな 時間 に なんJ やっ てる 奴 って いる の ? _end_ _start_ こんな 時間 に なんJ 民 が 好き な ん や が _end_ _start_ こんな 時間 に なんJ し てる 奴 って いる の ? _end_ _start_ こんな 時間 に なんJ やっ てる 奴 が いる ん や が _end_ _start_ こんな 時間 に なんJ やっ てる 奴 の お るか ? _end_ # 「ラーメン」から始まるスレタイ _start_ ラーメン 買っ て き たら どう なっ た ん や ? _end_ _start_ ラーメン ( _num_ ) だ けど 駅 の トイレ で 泣い てる _end_ _start_ ラーメン に なっ て き たら どう なる ん や ? _end_ _start_ ラーメン 買っ て き た ん や けど 質問 ある ? _end_ _start_ ラーメン 買っ て き たら どう し たら いい の ? _end_
※ _start_, _end_は開始と終了を表す特殊トークン、_num_は数字を表すトークン、WARATOKENは「w」が連続することを意味するトークン
注意
言語処理とかわからない人が書いているので、いろいろ間違えているかもしれません。
生成器の概要
生成するスレタイの開始Token列(0文字以上)が与えられた時に、
その開始Token列からはじまるスレタイをn個を生成します。
※ここでは、形態素や特殊トークン(開始、未知語を表すトークンなど)をまとめてTokenと呼びます。
中身はToken列から、次のTokenを予測するモデルで実装していて、
これを開始Token(_start_)から初めて、終了Token(_end_)がでるまで繰り返すことでスレタイを生成します。
Token予測モデルは、RNNの1つであるLSTMで実装されていています。 概念図は下のような感じです。
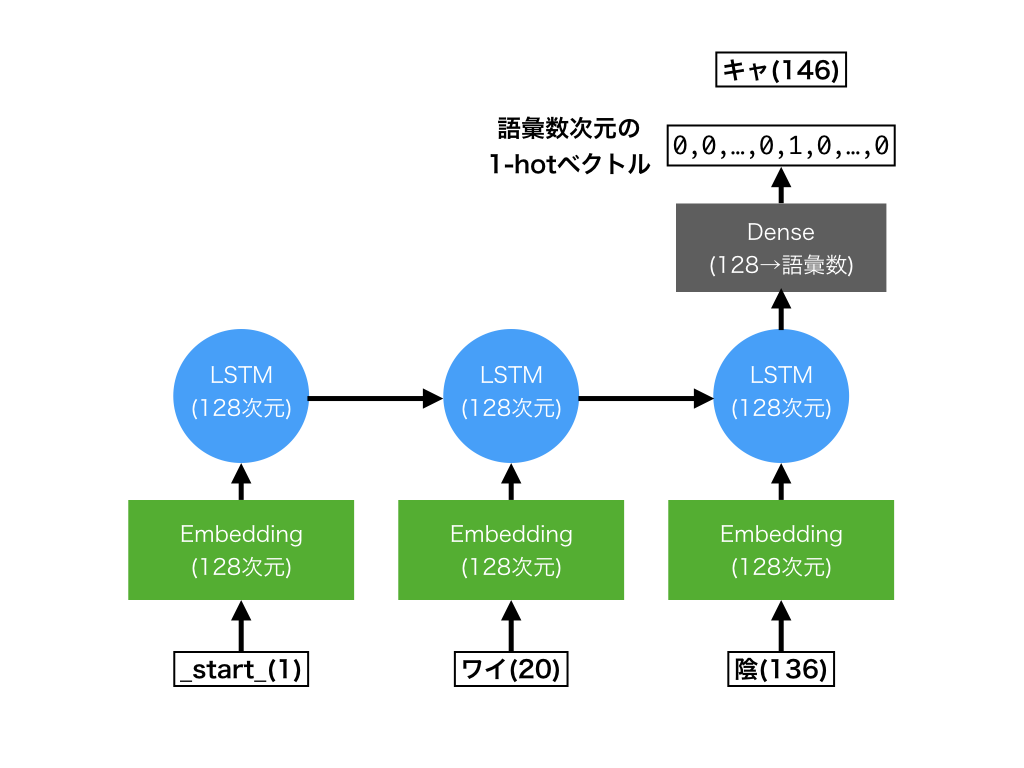
- 入力:Tokenのインデックス列(図内の
1,20,136。最大20個まで) - 出力:次のTokenを表すインデックス(図内の
146)
次元数とかは適当です。
詳細
ブログではポイントとなる部分のみを説明します。 詳しい内容はソースコードを読んでいただければと思います。
環境構築
今回はNvidia-dockerを使って環境構築をしました。 以下のサイトが非常に参考になりました。
生成器学習に必要なパッケージをDockerfileに書いておくと、 開発環境再現できて便利です。→ Dockerfile
なんJスレタイの取得
学習データとなるなんJのスレタイを5chの過去ログをクロールして、いい感じにスレタイを取得します。規模は2万スレくらいです。
特筆すべきところは無いので中身は省略します。→ スレタイ取得のソースコード
wikipediaコーパスの取得
wikipediaコーパスは、Embedding層の事前学習に利用します。
http://www.asahi.com/shimbun/medialab/word_embedding/を利用することも考えましたが、スレタイ固有の表現が語彙に入っていないと思ったのでword2vecを別途学習します。
wikipediaは親切にもダンプデータを公開しているので、curlで取得可能です。
Wikipedia:データベースダウンロード - Wikipedia
また、wikiextractorを利用して前処理します。
$ curl https://dumps.wikimedia.org/jawiki/latest/jawiki-latest-pages-articles.xml.bz2 -O $ python3 WikiExtractor.py --filter_disambig_pages -b 50M -o extracted jawiki-latest-pages-articles.xml.bz2 $ find extracted -name 'wiki*' -exec cat {} \; > jawiki.xml
tokenize
取得したスレタイ、wikipediaをTokenizeします。 tokenizeにはmecabとneologdの辞書を利用します。
ここで以下の前処理も行っています
- NFKC正規化
- 数字、一部の顔文字、「w」の連続をTOKEN化
word2vecの学習
Embedding層の初期値に使うため、gensimのword2vecを使ってTokenの分散表現を学習します。 このとき、スレタイ固有のTokenも語彙に入れるために、wikipediaとスレタイの両方を使って学習します。
初期値に使うだけなので、だいたい学習できていれば良いと思います。
# wikipedia, スレタイのデータからword2vecを学習 $ python3 word2vec_train.py "data/*.txt" data/w2v.dat # 動作確認(引数で与えたTokenと類似したTokenを取得) $ python3 word2vec_test.py data/w2v.dat "東京" 大阪 0.9098623991012573 名古屋 0.8524906039237976 福岡 0.8452504873275757 札幌 0.7933300733566284 神戸 0.7872719764709473 関西 0.7716591358184814 神奈川 0.7698613405227661 京都 0.7634186744689941 埼玉 0.7461172342300415 千葉 0.7347638607025146
スレタイ生成器の学習
学習自体は以下のコマンドでできます。
$ python3 train.py config.yaml ... _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input (InputLayer) (None, 20) 0 _________________________________________________________________ embedding_1 (Embedding) (None, 20, 128) 11004928 _________________________________________________________________ lstm_1 (LSTM) (None, 128) 131584 _________________________________________________________________ dropout_1 (Dropout) (None, 128) 0 _________________________________________________________________ dense_1 (Dense) (None, 20002) 2580258 ================================================================= Total params: 13,716,770 Trainable params: 13,716,770 Non-trainable params: 0 _________________________________________________________________ ...
ここでは、工夫した点についていくつか説明します。
gensimのword2vecから入力語彙にあわせたEmbedding層を作成する
gensimのkeyedvectorsにはkerasのEmbedding層を取得するget_keras_embedding
メソッドがあります。
models.keyedvectors – Store and query word vectors — gensim
しかし、wikipediaの語彙の中でスレタイで出現する語彙は1/10程度です。 そのため、wikipediaのコーパスを使って学習したword2vecをそのままEmbedding層に変換すると、大半の重みを使われずメモリがもったいないです。 私のGTX 1050 Tiでは、配列確保の時点でGUPのメモリが足りなくなりました。
また、いまのget_keras_embeddingはmask_zeroオプションに対応していないため、
入力長が可変のRNNと併用するのに向いていません。
mask_zeroについて: Embeddingレイヤー - Keras Documentation
そこで、以下のような感じで入力語彙に利用する語の重みだけ取得して、Embedding層を作ります。
from keras.preprocessing.text import Tokenizer from keras.layers import Embedding # 入力コーパスでkerasのtokenizerをfitする tokenizer = Tokenizer(num_words=None, lower=False, filters="") tokenizer.fit_on_texts(thread_title_sentences) # 学習済みのword2vecから、入力コーパスに出現する語の重みだけをtarget_weigths_listに入れる w2v = word2vec.Word2Vec.load(word2vec_path) original_weights = w2v.wv.syn0 target_weigths_list = [np.zeros(original_weights.shape[1])] # mask_zero用 wcounts = list(tokenizer.word_counts.items()) wcounts.sort(key=lambda x: x[1], reverse=True) for word, _ in wcounts: idx = w2v.wv.vocab[word].index target_weigths_list.append(original_weights[idx]) # target_weigths_listを元にEmbeddingレイヤーを作成 embedding_matrix = np.vstack(target_weigths_list) emb_layer = Embedding( input_dim=embedding_matrix.shape[0], output_dim=embedding_matrix.shape[1], weights=[embedding_matrix], trainable=True, mask_zero=True )
未知語の導入
入力語彙は9万程度あるのですが、出力の語彙は出現頻度の大きい2万としています。 語彙から漏れた後は未知語として学習して、生成時には利用しません。
生成する
beam searchっぽい感じでスレタイを生成します。短いスレタイが出がちなので10Token以上のスレタイを出力します。 スレタイの下に書いているのは生成した語の最終層の重みの積で、大きければなんJ度合いが高いことを表します。
# prefixで指定したワードから始まるスレタイを生成 $ python3 gen.py config.yaml -n 5 --prefix "ワイ" ... _start_ ワイ 陰 キャ だ けど 駅 の トイレ で 泣い てる _end_ 4.75191054636e-07 _start_ ワイ ( _num_ ) だ けど 駅 の トイレ で 泣い てる _end_ 2.62613424411e-07 _start_ ワイ しか 見 て ない こと を し て しまう WARATOKEN _end_ 3.5584431935e-08 _start_ ワイ しか 見 て ない こと に なっ て しまう WARATOKEN _end_ 2.92392169464e-08 _start_ ワイ 「 お前 ら が 好き な ん です か ?」 _end_ 2.72264028929e-08
考察とか
頻出語に引っ張られる
過学習気味にしたこともありますが、頻出語に引っ張られる傾向があり、 似たようなスレタイが生成されやすいようです。
prefix指定がない場合の生成例。「【」という語が強すぎる・・・。
_start_ 【 TBS 】 日本シリーズ _num_ ソフトバンク × DeNA ★ _num_ _end_ _start_ 【 悲報 】 なんJ に 自信 ニキ 来 て くれ _end_ _start_ 【 悲報 】 ワイ に 自信 ニキ 来 て くれ _end_ _start_ 【 悲報 】 なんJ 民 ワイ しか 見 て ない _end_ _start_ 【 急募 】 なんJ に 自信 ニキ お るか ? _end_ _start_ 【 悲報 】 なんJ に 自信 ニキ お るか ? _end_ _start_ 【 急募 】 なんJ に 自信 ニキ 来 て くれ _end_ _start_ 【 悲報 】 ワイ なんJ 民 しか 見 て ない _end_ _start_ 【 悲報 】 なんJ 民 ガイジ に なっ て しまう _end_ _start_ 【 悲報 】 ワイ に 自信 ニキ き て くれ _end_ _start_ 【 TBS 】 日本シリーズ DeNA × ソフトバンク × DeNA ★ _num_ _end_ _start_ 【 悲報 】 なんJ 民 ガチ で ガイジ だっ た _end_
うまく揺らせると良いのですが、どうすればよいかはわかりませんでした。
なんとなく構造的なものを捉えられている
三大がつくときは、「三大〜「A」「B」あとひとつは?」みたいなスレが多いです。 内容はともかくとして、スレタイの構造を捉えた、カギ括弧が複数連続するタイトルが生成されやすくなっています。(そもそもカッコをちゃんと閉じることもすごい)
prefixが「三大」のときの生成例
_start_ 三大 好き な なんJ 民 「 WARATOKEN 」 「 _num_ 」 _end_ _start_ 三大 【 急募 】 ワイ に 自信 ニキ 来 て くれ _end_ _start_ 三大 好き な なんJ 民 「 _num_ 」 「 _num_ 」 _end_ _start_ 三大 誰 も やっ て ない の は ない か ? _end_ _start_ 三大 好き な なんJ 民 「 ない 」 ← これ WARATOKEN _end_ _start_ 三大 【 TBS 】 日本シリーズ DeNA × ソフトバンク × DeNA ★ _num_ _end_ _start_ 三大 好き な なんJ 民 「 な 」 「 WARATOKEN 」 _end_ _start_ 三大 好き な なんJ 民 「 ない 」 「 _num_ 」 _end_ _start_ 三大 好き な なんJ 民 「 い 」 「 _num_ 」 _end_ _start_ 三大 好き な なんJ 民 「 だ 」 「 WARATOKEN 」 _end_ _start_ 三大 好き な なんJ 民 「 な 」 「 _num_ 」 _end_ _start_ 三大 好き な なんJ 民 「 WARATOKEN 」 「 WARATOKEN 」 _end_ _start_ 三大 好き な なんJ 民 「 だ 」 「 _num_ 」 _end_ _start_ 三大 WARATOKEN 「 _num_ 」 「 _num_ 」 「 _num_ 」 _end_
参考にさせていただいたページ
- Ubuntu 16.04 LTS で NVIDIA Docker を使ってみる - CUBE SUGAR CONTAINER
- gensimを使ってKerasのEmbedding層を取得する - Ahogrammer
- pythonのgensimライブラリを利用して日本語wikipediaの全文からword2vecを学習させるまでの全手順 - marmarossa’s blog
- 【Python】日本語Wikipediaのダンプデータから本文を抽出する - プログラムは、用いる言葉の選択で決まる
- deep learning - Index of Embedding layer with zero padding in Keras - Stack Overflow