(続)macOS SierraでKarabinerの「EISUU to Escape(入力ソースが日本語以外の場合のみ)」を実現する
Deprecated
もっと良い方法を見つけましたので、こちらを利用して下さい。
以下、元記事です。
以前の記事で、HammerspoonとKarabiner-Elementsを使って、 擬似的にKarabinerの「EISUU to Escape(入力ソースが日本語以外の場合のみ)」(下図)を 実現する方法を紹介しました。

→macOS SierraでKarabinerの「EISUU to Escape(入力ソースが日本語以外の場合のみ)」を実現する - のどあめ
この度、Karabiner-ElementsのComplex Modificationsを使うことで、 Karabiner-Elementsのみで実現する方法を見つけたので紹介します。(しかもこちらのほうが安定する)
参考にしたページ
- TerminalやMacVimでEsc (or ^[)キーで日本語IMEを英数に切り替える(Karabiner-Elementsによる設定) - Qiita
- 今回の方法はほぼこちらの方のアイデアをそのまま利用しています。
実現方法
まずは、この機能を実現するComplex Modificationsを作成します。
.config/karabiner/assets/complex_modifications/EisuuToEscapeInTerminal.json
に以下のようなjsonファイルを配置します。
{ "title": "Terminal等で入力ソースが日本語以外の場合に英数をEscapeに変更する", "rules": [ { "description": "Terminal等で入力ソースが日本語以外の場合に英数をEscapeに変更する", "manipulators": [ { "type": "basic", "from": { "key_code": "japanese_eisuu", "modifiers": { "optional": [ "any" ] } }, "to": [ { "key_code": "japanese_eisuu"}, { "set_variable": {"name": "jp_input", "value": 0}} ], "conditions": [ { "type": "variable_if", "name": "jp_input", "value": 1 }, { "type": "frontmost_application_if", "bundle_identifiers": [ "^com\\.apple\\.Terminal$", "^org\\.vim\\.", "^com\\.googlecode\\.iterm2$" ] } ] }, { "type": "basic", "from": { "key_code": "japanese_eisuu", "modifiers": { "optional": [ "any" ] } }, "to": [ { "key_code": "escape"} ], "conditions": [ { "type": "variable_if", "name": "jp_input", "value": 0 }, { "type": "frontmost_application_if", "bundle_identifiers": [ "^com\\.apple\\.Terminal$", "^org\\.vim\\.", "^com\\.googlecode\\.iterm2$" ] } ] }, { "type": "basic", "from": { "key_code": "japanese_kana", "modifiers": { "optional": [ "any" ] } }, "to": [ { "key_code": "japanese_kana"}, { "set_variable": {"name": "jp", "value": 1}} ], "conditions": [ { "type": "frontmost_application_if", "bundle_identifiers": [ "^com\\.apple\\.Terminal$", "^org\\.vim\\.", "^com\\.googlecode\\.iterm2$" ] } ] } ] } ] }
次に、Karabiner-ElementsのPreferenceから、 「Complex Modifications」→「Add rule」→「Terminal等で入力ソースが日本語以外の場合に英数をEscapeに変更する」を有効にします。

以上で、擬似的に日本語入力でないときのみ英数キーがEscape変わります。
ザックリした仕組み
- 「かな」と「英数」で、変数
jp_inputに1, 0を代入します。 - 変数
jp_inputが0のときのみ「英数」を「Escape」に変更します。
これで、「EISUU to Escape(入力ソースが日本語以外の場合のみ)」が擬似的に実現できます。
まとめ
KerasとgensimでなんJスレタイ生成器を構築する(1回目)
最近リベンジしました
初めて買ったGPU(GeForce GTX 1050 Ti)を試用するために、 Kerasとgensimを使ってなんJスレタイ生成器をつくってみました。
生成サンプルは以下のとおりです。似たようなものが多いですが、なんJ感がでていて良い感じなものができました。
# 「【悲報」から始まるスレタイ _start_ 【 悲報 】 なんJ 民 とんでも ない こと を し て しまう _end_ _start_ 【 悲報 】 なんJ 民 さん ガチ で やっ て い た _end_ _start_ 【 悲報 】 なんJ 民 さん とんでも ない こと を し て しまう _end_ _start_ 【 悲報 】 なんJ 民 とんでも ない 事 を し て しまう _end_ _start_ 【 悲報 】 なんJ 民 に 自信 ニキ 来 て くれ や _end_ # 「ワイ」から始まるスレタイ _start_ ワイ 陰 キャ だ けど 駅 の トイレ で 泣い てる _end_ _start_ ワイ ( _num_ ) だ けど 駅 の トイレ で 泣い てる _end_ _start_ ワイ しか 見 て ない こと を し て しまう WARATOKEN _end_ _start_ ワイ しか 見 て ない こと に なっ て しまう WARATOKEN _end_ _start_ ワイ 「 お前 ら が 好き な ん です か ?」 _end_ # 「こんな」から始まるスレタイ _start_ こんな 時間 に なんJ やっ てる 奴 って いる の ? _end_ _start_ こんな 時間 に なんJ 民 が 好き な ん や が _end_ _start_ こんな 時間 に なんJ し てる 奴 って いる の ? _end_ _start_ こんな 時間 に なんJ やっ てる 奴 が いる ん や が _end_ _start_ こんな 時間 に なんJ やっ てる 奴 の お るか ? _end_ # 「ラーメン」から始まるスレタイ _start_ ラーメン 買っ て き たら どう なっ た ん や ? _end_ _start_ ラーメン ( _num_ ) だ けど 駅 の トイレ で 泣い てる _end_ _start_ ラーメン に なっ て き たら どう なる ん や ? _end_ _start_ ラーメン 買っ て き た ん や けど 質問 ある ? _end_ _start_ ラーメン 買っ て き たら どう し たら いい の ? _end_
※ _start_, _end_は開始と終了を表す特殊トークン、_num_は数字を表すトークン、WARATOKENは「w」が連続することを意味するトークン
注意
言語処理とかわからない人が書いているので、いろいろ間違えているかもしれません。
生成器の概要
生成するスレタイの開始Token列(0文字以上)が与えられた時に、
その開始Token列からはじまるスレタイをn個を生成します。
※ここでは、形態素や特殊トークン(開始、未知語を表すトークンなど)をまとめてTokenと呼びます。
中身はToken列から、次のTokenを予測するモデルで実装していて、
これを開始Token(_start_)から初めて、終了Token(_end_)がでるまで繰り返すことでスレタイを生成します。
Token予測モデルは、RNNの1つであるLSTMで実装されていています。 概念図は下のような感じです。
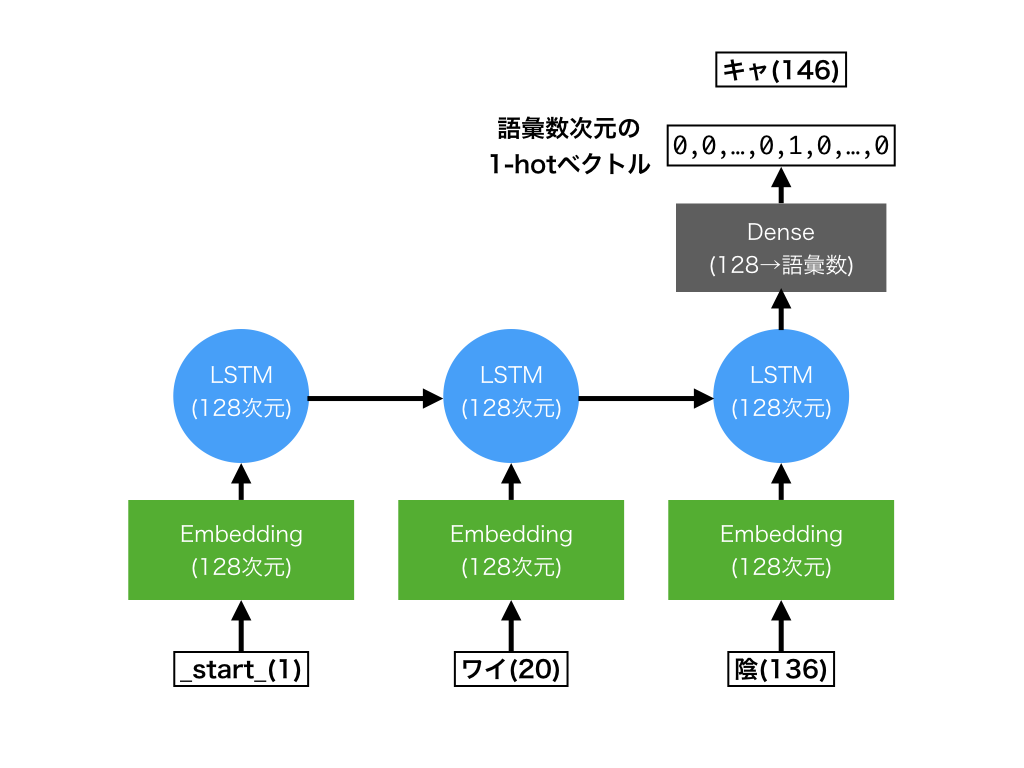
- 入力:Tokenのインデックス列(図内の
1,20,136。最大20個まで) - 出力:次のTokenを表すインデックス(図内の
146)
次元数とかは適当です。
詳細
ブログではポイントとなる部分のみを説明します。 詳しい内容はソースコードを読んでいただければと思います。
環境構築
今回はNvidia-dockerを使って環境構築をしました。 以下のサイトが非常に参考になりました。
生成器学習に必要なパッケージをDockerfileに書いておくと、 開発環境再現できて便利です。→ Dockerfile
なんJスレタイの取得
学習データとなるなんJのスレタイを5chの過去ログをクロールして、いい感じにスレタイを取得します。規模は2万スレくらいです。
特筆すべきところは無いので中身は省略します。→ スレタイ取得のソースコード
wikipediaコーパスの取得
wikipediaコーパスは、Embedding層の事前学習に利用します。
http://www.asahi.com/shimbun/medialab/word_embedding/を利用することも考えましたが、スレタイ固有の表現が語彙に入っていないと思ったのでword2vecを別途学習します。
wikipediaは親切にもダンプデータを公開しているので、curlで取得可能です。
Wikipedia:データベースダウンロード - Wikipedia
また、wikiextractorを利用して前処理します。
$ curl https://dumps.wikimedia.org/jawiki/latest/jawiki-latest-pages-articles.xml.bz2 -O $ python3 WikiExtractor.py --filter_disambig_pages -b 50M -o extracted jawiki-latest-pages-articles.xml.bz2 $ find extracted -name 'wiki*' -exec cat {} \; > jawiki.xml
tokenize
取得したスレタイ、wikipediaをTokenizeします。 tokenizeにはmecabとneologdの辞書を利用します。
ここで以下の前処理も行っています
- NFKC正規化
- 数字、一部の顔文字、「w」の連続をTOKEN化
word2vecの学習
Embedding層の初期値に使うため、gensimのword2vecを使ってTokenの分散表現を学習します。 このとき、スレタイ固有のTokenも語彙に入れるために、wikipediaとスレタイの両方を使って学習します。
初期値に使うだけなので、だいたい学習できていれば良いと思います。
# wikipedia, スレタイのデータからword2vecを学習 $ python3 word2vec_train.py "data/*.txt" data/w2v.dat # 動作確認(引数で与えたTokenと類似したTokenを取得) $ python3 word2vec_test.py data/w2v.dat "東京" 大阪 0.9098623991012573 名古屋 0.8524906039237976 福岡 0.8452504873275757 札幌 0.7933300733566284 神戸 0.7872719764709473 関西 0.7716591358184814 神奈川 0.7698613405227661 京都 0.7634186744689941 埼玉 0.7461172342300415 千葉 0.7347638607025146
スレタイ生成器の学習
学習自体は以下のコマンドでできます。
$ python3 train.py config.yaml ... _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input (InputLayer) (None, 20) 0 _________________________________________________________________ embedding_1 (Embedding) (None, 20, 128) 11004928 _________________________________________________________________ lstm_1 (LSTM) (None, 128) 131584 _________________________________________________________________ dropout_1 (Dropout) (None, 128) 0 _________________________________________________________________ dense_1 (Dense) (None, 20002) 2580258 ================================================================= Total params: 13,716,770 Trainable params: 13,716,770 Non-trainable params: 0 _________________________________________________________________ ...
ここでは、工夫した点についていくつか説明します。
gensimのword2vecから入力語彙にあわせたEmbedding層を作成する
gensimのkeyedvectorsにはkerasのEmbedding層を取得するget_keras_embedding
メソッドがあります。
models.keyedvectors – Store and query word vectors — gensim
しかし、wikipediaの語彙の中でスレタイで出現する語彙は1/10程度です。 そのため、wikipediaのコーパスを使って学習したword2vecをそのままEmbedding層に変換すると、大半の重みを使われずメモリがもったいないです。 私のGTX 1050 Tiでは、配列確保の時点でGUPのメモリが足りなくなりました。
また、いまのget_keras_embeddingはmask_zeroオプションに対応していないため、
入力長が可変のRNNと併用するのに向いていません。
mask_zeroについて: Embeddingレイヤー - Keras Documentation
そこで、以下のような感じで入力語彙に利用する語の重みだけ取得して、Embedding層を作ります。
from keras.preprocessing.text import Tokenizer from keras.layers import Embedding # 入力コーパスでkerasのtokenizerをfitする tokenizer = Tokenizer(num_words=None, lower=False, filters="") tokenizer.fit_on_texts(thread_title_sentences) # 学習済みのword2vecから、入力コーパスに出現する語の重みだけをtarget_weigths_listに入れる w2v = word2vec.Word2Vec.load(word2vec_path) original_weights = w2v.wv.syn0 target_weigths_list = [np.zeros(original_weights.shape[1])] # mask_zero用 wcounts = list(tokenizer.word_counts.items()) wcounts.sort(key=lambda x: x[1], reverse=True) for word, _ in wcounts: idx = w2v.wv.vocab[word].index target_weigths_list.append(original_weights[idx]) # target_weigths_listを元にEmbeddingレイヤーを作成 embedding_matrix = np.vstack(target_weigths_list) emb_layer = Embedding( input_dim=embedding_matrix.shape[0], output_dim=embedding_matrix.shape[1], weights=[embedding_matrix], trainable=True, mask_zero=True )
未知語の導入
入力語彙は9万程度あるのですが、出力の語彙は出現頻度の大きい2万としています。 語彙から漏れた後は未知語として学習して、生成時には利用しません。
生成する
beam searchっぽい感じでスレタイを生成します。短いスレタイが出がちなので10Token以上のスレタイを出力します。 スレタイの下に書いているのは生成した語の最終層の重みの積で、大きければなんJ度合いが高いことを表します。
# prefixで指定したワードから始まるスレタイを生成 $ python3 gen.py config.yaml -n 5 --prefix "ワイ" ... _start_ ワイ 陰 キャ だ けど 駅 の トイレ で 泣い てる _end_ 4.75191054636e-07 _start_ ワイ ( _num_ ) だ けど 駅 の トイレ で 泣い てる _end_ 2.62613424411e-07 _start_ ワイ しか 見 て ない こと を し て しまう WARATOKEN _end_ 3.5584431935e-08 _start_ ワイ しか 見 て ない こと に なっ て しまう WARATOKEN _end_ 2.92392169464e-08 _start_ ワイ 「 お前 ら が 好き な ん です か ?」 _end_ 2.72264028929e-08
考察とか
頻出語に引っ張られる
過学習気味にしたこともありますが、頻出語に引っ張られる傾向があり、 似たようなスレタイが生成されやすいようです。
prefix指定がない場合の生成例。「【」という語が強すぎる・・・。
_start_ 【 TBS 】 日本シリーズ _num_ ソフトバンク × DeNA ★ _num_ _end_ _start_ 【 悲報 】 なんJ に 自信 ニキ 来 て くれ _end_ _start_ 【 悲報 】 ワイ に 自信 ニキ 来 て くれ _end_ _start_ 【 悲報 】 なんJ 民 ワイ しか 見 て ない _end_ _start_ 【 急募 】 なんJ に 自信 ニキ お るか ? _end_ _start_ 【 悲報 】 なんJ に 自信 ニキ お るか ? _end_ _start_ 【 急募 】 なんJ に 自信 ニキ 来 て くれ _end_ _start_ 【 悲報 】 ワイ なんJ 民 しか 見 て ない _end_ _start_ 【 悲報 】 なんJ 民 ガイジ に なっ て しまう _end_ _start_ 【 悲報 】 ワイ に 自信 ニキ き て くれ _end_ _start_ 【 TBS 】 日本シリーズ DeNA × ソフトバンク × DeNA ★ _num_ _end_ _start_ 【 悲報 】 なんJ 民 ガチ で ガイジ だっ た _end_
うまく揺らせると良いのですが、どうすればよいかはわかりませんでした。
なんとなく構造的なものを捉えられている
三大がつくときは、「三大〜「A」「B」あとひとつは?」みたいなスレが多いです。 内容はともかくとして、スレタイの構造を捉えた、カギ括弧が複数連続するタイトルが生成されやすくなっています。(そもそもカッコをちゃんと閉じることもすごい)
prefixが「三大」のときの生成例
_start_ 三大 好き な なんJ 民 「 WARATOKEN 」 「 _num_ 」 _end_ _start_ 三大 【 急募 】 ワイ に 自信 ニキ 来 て くれ _end_ _start_ 三大 好き な なんJ 民 「 _num_ 」 「 _num_ 」 _end_ _start_ 三大 誰 も やっ て ない の は ない か ? _end_ _start_ 三大 好き な なんJ 民 「 ない 」 ← これ WARATOKEN _end_ _start_ 三大 【 TBS 】 日本シリーズ DeNA × ソフトバンク × DeNA ★ _num_ _end_ _start_ 三大 好き な なんJ 民 「 な 」 「 WARATOKEN 」 _end_ _start_ 三大 好き な なんJ 民 「 ない 」 「 _num_ 」 _end_ _start_ 三大 好き な なんJ 民 「 い 」 「 _num_ 」 _end_ _start_ 三大 好き な なんJ 民 「 だ 」 「 WARATOKEN 」 _end_ _start_ 三大 好き な なんJ 民 「 な 」 「 _num_ 」 _end_ _start_ 三大 好き な なんJ 民 「 WARATOKEN 」 「 WARATOKEN 」 _end_ _start_ 三大 好き な なんJ 民 「 だ 」 「 _num_ 」 _end_ _start_ 三大 WARATOKEN 「 _num_ 」 「 _num_ 」 「 _num_ 」 _end_
参考にさせていただいたページ
- Ubuntu 16.04 LTS で NVIDIA Docker を使ってみる - CUBE SUGAR CONTAINER
- gensimを使ってKerasのEmbedding層を取得する - Ahogrammer
- pythonのgensimライブラリを利用して日本語wikipediaの全文からword2vecを学習させるまでの全手順 - marmarossa’s blog
- 【Python】日本語Wikipediaのダンプデータから本文を抽出する - プログラムは、用いる言葉の選択で決まる
- deep learning - Index of Embedding layer with zero padding in Keras - Stack Overflow
macOS SierraでKarabinerの「EISUU to Escape(入力ソースが日本語以外の場合のみ)」を実現する
Deprecated
もっと良い方法を見つけましたので、こちらを利用して下さい。
以下、元記事です。
macOS SierraからKarabinerが使えなくなりました。 公式サイトでは、Karabiner-Elementsへの移行を呼びかけていますが、 2017/09/16現在ではKarabinerの全ての機能を使うことはできないようです。
私が愛用していた「EISUU to Escape(入力ソースが日本語以外の場合のみ)」(下図)もその一つです。 今回は、HammerspoonとKarabiner-Elementsを使って擬似的にこの設定を再現しました。
注意
失敗するとKarabiner-Elementsの設定ファイル(~/config/karabiner/karabiner.json)が消えてしまいます。
必ずバックアップをとってから試すようにして下さい
実現方法
こちらの記事とほぼ同じ方法を使います。 日本語入力の切替時に、HammerspoonでKarabiner-Elementsの設定を切り替えます。
必要なアプリケーションをインストール
以下の2つをインストールします。
Karabiner-Elementsのプロファイルを作る
上の記事を参考に、Karabiner-Elementsのプロファイルを作成します。
今回は、日本語入力以外の設定である「Default」と 日本語入力中の設定である「Japanese」の2つのプロファイルを作成します。 設定項目はなんでも良いですが、 Defaultの方のみに、英数キーをEscapeにマッピングする設定をします。

また、Miscから「show profile name in menu bar」をONにしておくと、切り替わりがわかりやすくて良いと思います。
Karabinerの設定を変更するスクリプトを実装
以下のスクリプトを~/.hammerspoon/karabiner-switcher.pyに配置します。
※要実行権限
#!/usr/bin/env python # -*- encode: utf-8 -*- import os import sys import json def main(): if len(sys.argv) != 2: print("usage: {0} profile_name".format(sys.argv[0])) exit(1) home = os.environ['HOME'] fpath = os.path.join(home, ".config/karabiner/karabiner.json") with open(fpath) as f: conf = json.load(f) profile_name = sys.argv[1] select_flag = False for c in conf["profiles"]: c["selected"] = c["name"] == profile_name select_flag |= c["selected"] if not select_flag: print("profile_name[{0}] is not found".format(profile_name)) exit(1) with open(fpath, "w") as f: f.write(json.dumps(conf, indent=4, sort_keys=True)) if __name__ == "__main__": main()
Hammerspoonの設定
入力ソース切替で上のスクリプトを実行するよう、
~/.hammerspoon/init.luaを実装します。
以下はgoogle日本語入力の場合です。他のIMEを使っている場合はif文のところを変更して下さい。 IMEのSouceIDはコメントアウトしているprint文をconsoleから確認できます。
local home = os.getenv("HOME") function switchKarabiner() source_id = hs.keycodes.currentSourceID() -- print("source_id: " .. source_id .. "\n") if source_id == "com.google.inputmethod.Japanese.base" then hs.execute(home .. '/.hammerspoon/karabiner-switcher.py Japanese') else hs.execute(home .. '/.hammerspoon/karabiner-switcher.py Default') end end hs.keycodes.inputSourceChanged(switchKarabiner)
Hammerspoonの設定を反映させる
HammerspoonのReload Configを選びます。
これで日本語入力のON/OFFでKarabiner-ElementsのプロファイルがJapanese/Default が切り替わっていれば成功です。
まとめ
【Rust×WebAssembly】木構造グラフの描画でWebAssemblyの処理速度を検証
概要
- 力学的モデルを使った木構造グラフの描画を対象に
JavaScriptとWebAssembly(WASM)の処理速度比較をした - ノード数が大きいグラフの描画ではWebAssemblyのほうが1.7倍くらい早かった。
やりたいこと
過去に何人かの方がWebAssemblyとJavaScriptの処理速度をされています。
- http://qiita.com/akira_/items/55cf1f5911b14e265c6f
- http://qiita.com/akira_/items/846a457ea110c172f2a5
彼らによると、フィボナッチ数列やループ処理などのベンチマーク的なスクリプトは、WebAssemblyのほうが数倍程度早いそうです。
今回は、WebAssemblyが実際に使われそうな例で処理時間の比較を行いたいと思います。
検証対象
数倍の処理速度向上で恩恵を受ける例として描画計算があります。
今回は、グラフ描画アルゴリズムの一つである力学的モデルを用いた 木構造グラフの描画時間を、JavaScriptとWebAssemblyで比較したいと思います。
アルゴリズム参考:力学モデル (グラフ描画アルゴリズム) - Wikipedia
検証に用いたスクリプト

ざっくりした使い方
- num_nodesに木構造グラフをのノード数を入力する
- [Init Graph]を押下してグラフのノード位置を初期化する
- [Update by JavaScript]または[Update by WASM]を押下して、力学モデルを使ってノード位置を更新する
- 実行にかかった時間がtimeに表示される
※ animation flagをOFFにした場合は、ノード位置が収束するまで描画しない。
実装概要
dist/index.html
https://github.com/ykicisk/wasm_graph/blob/master/dist/index.html
src/js/main.js
https://github.com/ykicisk/wasm_graph/blob/master/src/js/main.js
※実際はBabelでdist/js/bundle.jsにトランスパイルされます。
- 指定されたノード数で木構造グラフを生成します。
- 描画に利用するノード・エッジの情報はWebAssemblyで利用しやすいように、ArrayではなくFloat32ArrayやInt32Arrayで定義します。
- グラフ初期化関数・グラフ描画関数を定義します。
- index.htmlにグラフ操作用のIF要素を追加します。
- 指定したノード数のグラフを生成します。
- 後述のGraphUpadaterを使ってグラフのノード位置を更新します。
src/js/GraphUpdater.js
https://github.com/ykicisk/wasm_graph/blob/master/src/js/main.js
※実際はBabelでdist/js/bundle.jsにトランスパイルされます。
- グラフのノード位置を更新するGraphUpadaterクラス。
- GraphUpdaterBase: 共通部分を実装した基底クラス
- 共通で利用するノードの速度を格納するFloat32Arrayの確保
- animation_flagによる処理切り替え
_update_loop()関数でイテレーション1回分の更新を行う。
- JavaScriptGraphUpdater: JavaScriptでグラフ更新するクラス
- RustGraphUpdater: WASMでグラフ更新するクラス
- GraphUpdaterBase: 共通部分を実装した基底クラス
JavaScriptのグラフ更新関数
ノードの座標{x,y}_list、速度{vx,vy}_listを更新して、
ノードの運動エネルギー合計を返します。
スクリプト内で使われている変数は以下の通り
COULOMB,BOUNCE,ATTENUATION: 定数{x,y}_list: 現在のノードのx, y座標(Float32Array){fx,fy}_list: ノードにかかる力のx, y成分(Float32Array){vx,vy}_list: ノードの速度のx, y成分(Float32Array)tmp_{x,y}_list: 前ステップのノードのx, y座標(Float32Array)edge_list: エッジ情報(i+1番目のノードとedge_list[i]番目のノードにエッジが貼ってある)(Int32Array)
_update_loop() { // init this.tmp_x_list.set(this.x_list); this.tmp_y_list.set(this.y_list); this.fx_list.fill(0.0); this.fy_list.fill(0.0); let energy = 0.0; for (let idx1 = 0; idx1 < this.num_nodes-1; idx1++){ for (let idx2 = idx1 + 1; idx2 < this.num_nodes; idx2++){ let dist_x = this.tmp_x_list[idx1] - this.tmp_x_list[idx2]; let dist_y = this.tmp_y_list[idx1] - this.tmp_y_list[idx2]; let rsq = Math.pow(dist_x, 2) + Math.pow(dist_y, 2); this.fx_list[idx1] += this.COULOMB * dist_x / rsq; this.fy_list[idx1] += this.COULOMB * dist_y / rsq; this.fx_list[idx2] -= this.COULOMB * dist_x / rsq; this.fy_list[idx2] -= this.COULOMB * dist_y / rsq; } } for (var i = 0; i < (this.num_nodes - 1);i++) { let idx1 = this.edge_list[i]; let idx2 = i+1; let dist_x = this.tmp_x_list[idx2] - this.tmp_x_list[idx1]; let dist_y = this.tmp_y_list[idx2] - this.tmp_y_list[idx1]; this.fx_list[idx1] += this.BOUNCE * dist_x; this.fy_list[idx1] += this.BOUNCE * dist_y; this.fx_list[idx2] -= this.BOUNCE * dist_x; this.fy_list[idx2] -= this.BOUNCE * dist_y; } for (let idx = 0; idx < this.num_nodes; idx++){ this.vx_list[idx] = (this.vx_list[idx] + this.fx_list[idx]) * this.ATTENUATION; this.vy_list[idx] = (this.vy_list[idx] + this.fy_list[idx]) * this.ATTENUATION; this.x_list[idx] += this.vx_list[idx]; this.y_list[idx] += this.vy_list[idx]; energy += Math.pow(this.vx_list[idx], 2) * Math.pow(this.vy_list[idx], 2); } return energy; }
WASMのグラフ更新関数
処理をWebAssemblyに委任します。
constructor() { ... this.wasm_update_loop = Module.cwrap('wasm_update_loop', 'number', ['number', 'number', 'number', 'number', 'number', 'number']); ... }
_update_loop() { return this.wasm_update_loop(this.num_nodes, this.edge_list.byteOffset, this.x_list.byteOffset, this.y_list.byteOffset, this.vx_list.byteOffset, this.vy_list.byteOffset); }
src/main.rs(WebAssembly)の実装はほぼJavaScriptと同じです。
#[no_mangle] pub extern "C" fn wasm_update_loop(num_nodes_i32: i32, edge_list_ptr: *const i32, x_list_ptr: *mut f32, y_list_ptr: *mut f32, vx_list_ptr: *mut f32, vy_list_ptr: *mut f32) -> f32 { let mut energy: f32 = 0.0; unsafe { let num_nodes = num_nodes_i32 as usize; let mut x_list: &mut [f32] = std::slice::from_raw_parts_mut(x_list_ptr, num_nodes); let mut y_list: &mut [f32] = std::slice::from_raw_parts_mut(y_list_ptr, num_nodes); let mut vx_list: &mut [f32] = std::slice::from_raw_parts_mut(vx_list_ptr, num_nodes); let mut vy_list: &mut [f32] = std::slice::from_raw_parts_mut(vy_list_ptr, num_nodes); let edge_list: &[i32] = std::slice::from_raw_parts(edge_list_ptr, num_nodes - 1); let mut fx_list = vec![0.0; num_nodes]; let mut fy_list = vec![0.0; num_nodes]; let mut tmp_x_list = vec![0.0; num_nodes]; let mut tmp_y_list = vec![0.0; num_nodes]; tmp_x_list.clone_from_slice(x_list); tmp_y_list.clone_from_slice(y_list); for idx1 in 0..num_nodes - 1 { for idx2 in idx1 + 1..num_nodes { let dist_x = x_list[idx1] - tmp_x_list[idx2]; let dist_y = y_list[idx1] - tmp_y_list[idx2]; let rsq = dist_x * dist_x + dist_y * dist_y; fx_list[idx1] += COULOMB * dist_x / rsq; fy_list[idx1] += COULOMB * dist_y / rsq; fx_list[idx2] -= COULOMB * dist_x / rsq; fy_list[idx2] -= COULOMB * dist_y / rsq; } } for i in 0..num_nodes - 1 { let idx1 = edge_list[i] as usize; let idx2 = i + 1; let dist_x = tmp_x_list[idx2] - tmp_x_list[idx1]; let dist_y = tmp_y_list[idx2] - tmp_y_list[idx1]; fx_list[idx1] += BOUNCE * dist_x; fy_list[idx1] += BOUNCE * dist_y; fx_list[idx2] -= BOUNCE * dist_x; fy_list[idx2] -= BOUNCE * dist_y; } for idx in 0..num_nodes { vx_list[idx] = (vx_list[idx] + fx_list[idx]) * ATTENUATION; vy_list[idx] = (vy_list[idx] + fy_list[idx]) * ATTENUATION; x_list[idx] += vx_list[idx]; y_list[idx] += vy_list[idx]; energy += vx_list[idx].powf(2.0) * vy_list[idx].powf(2.0); } } energy }
検証方法
ノード位置をランダムに初期化した木構造グラフに対して力学的モデルを適用します。 ノード数が同じグラフを3個生成して、ノード位置が収束して描画が完了するまでの時間の平均を比較します。
先のスクリプトのanimation flagはOFFで比較します。
検証結果
結果は下表です。 WebAssemblyを使うことで、ノード数が大きいときの処理時間が60%程度に抑えられることが読み取れます。

力学的モデルを利用した木構造グラフの描画においても、 WebAssemblyを用いることで計算時間短縮の恩恵を得られることがわかりました。
感想
- WebAssemblyを使っても処理が数倍早い程度なので、応用先は考える必要がありそう。
- WebAssemblyはまだまだ安定していないようにみえる。
- 不具合があったときに、エラー文でググっても出てこない
- 再起動すると動くようになる謎バグとかが多い
- 当たり前だがJavaScriptとmallocの相性が悪い。例えばClassにDestructorがないのでメモリ管理が大変。
- WebAssemblyに状態をもたせるより、JavaScriptで状態を一元管理してWebAssemblyに引数で必要な情報だけ渡したほうが良さそう。
- Rustの実装がunsafeのオンパレードになるなら、普通にCやC++で実装したほうがわかりやすそう。
参考ページ
- http://leko.jp/archives/699
- 力学的モデル実装の参考にさせていただきました。
【Rust×WebAssembly】Rust JavaScript間でデータをやり取りする
概要
- WebAssemblyを使ってJavaScriptからRustの関数を使うときの話
- JavaScript<->Rustのデータのやり取りをする方法をまとめました。
- 数値、String、Arrayで書き方が違うみたいです。
参考にしたページ
- https://sbfl.net/blog/2017/03/13/rust-wasm/
- 全体的なWebAssemblyの動かし方について参考にさせていただきました。
- http://stackoverflow.com/questions/24145823/rust-ffi-c-string-handling
- Stringの受け渡しについて参考にさせていただきました。
- http://qiita.com/shizu-oka/items/d386001b45f5cd2aacab
- Arrayの受け渡しについて参考にさせていただきました。
Rust, Webassemblyとは
省略
必要なもの
- RustをWebAssemblyにコンパイルできる環境(Rust>=1.17.0)
- こちらのブログが非常に参考になります。
- https://sbfl.net/blog/2017/03/13/rust-wasm/
- Google Chrome等のWebAssemblyが動かせる環境
- Web Server的なもの
データやり取りの方法
共通
src/main.rsをwasm/wasm_test.wasm,wasm/wasm_test.jsにコンパイルします。index.htmlでwasm/wasm_test.wasmをロードしたらsrc/main.jsが実行されます。src/main.jsから、src/main.rsで実装したrustの関数を呼び出します。
index.html
<!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8"> <title>wasm test</title> <script> var Module = {}; fetch('wasm/wasm_test.wasm') .then((response) => response.arrayBuffer()) .then((wasm) => { Module.wasmBinary = wasm; const scriptElem = document.createElement('script'); scriptElem.src = 'wasm/wasm_test.js'; scriptElem.addEventListener('load', (e) => { const mainScriptElem = document.createElement('script'); mainScriptElem.src = 'src/main.js'; document.body.appendChild(mainScriptElem); }); document.body.appendChild(scriptElem); }); </script> </head> <body> <div id="number"></div> <div id="string"></div> <div id="array"></div> </body> </html>
想定する結果
- JavaScriptからRustに渡された値は
println!マクロによってconsole.logに出力します。 - RustからJavaScriptに渡された値は
divに出力されます。 - githubのコードを動かすと↓のようになります。

数値の受け渡し
数値(js<->rust)
数値を受け渡す場合は、JavaScript、Rustともに普通に関数を書けば良いです。
i32やf64等数値っぽい型はそのまま渡せますが、usizeなんかは渡せませんでした。
src/main.js
// number: js <-> rust const wasm_number = Module.cwrap('wasm_number', 'number', ['number', 'number']); document.getElementById('number').innerText = wasm_number(3, 4.2);
src/main.rs
#[no_mangle] pub extern "C" fn wasm_number(n: i32, m: f64) -> f64 { m + (n as f64) * 2.0 }
文字列の受け渡し
文字列(js->rust)
JavaScriptの文字列はRustで*c_char型として受け取ります。
これをRustのString型に変換する必要があります。
src/main.js
const wasm_string_to_rust = Module.cwrap('wasm_string_to_rust', null, ['string']); wasm_string_to_rust("string from js");
src/main.rs
use std::os::raw::c_char; use std::ffi::CStr; use std::str; #[no_mangle] pub extern "C" fn wasm_string_to_rust(c_buf: *const c_char) { let c_str: &CStr = unsafe { CStr::from_ptr(c_buf) }; let buffer: &[u8] = c_str.to_bytes(); let rust_str: &str = str::from_utf8(buffer).unwrap(); let rust_string: String = rust_str.to_owned(); println!("{}", rust_string); }
文字列(rust->js)
rustの文字列をjsに渡すためには、同様に*c_char型で返せば良いですが、
Rustの関数内で作った文字列のアドレスをas_ptrで返してしまうと、
関数から抜けたときに文字列のメモリが開放されてしまいます。
今回は、lazy_staticを利用してstaticなStringを保持して、
勝手にメモリが開放されないようにしています。
JavaScriptから関数を呼ぶ場合はこの処理をなくしても動作するそうですが、 Rustから関数を呼ぶとメモリ開放されて値を受け取れないので、念のためやっておいた方が良いと思います。
src/main.js
const wasm_string_to_js = Module.cwrap('wasm_string_to_js', 'string', []); document.getElementById('string').innerText = wasm_string_to_js();
src/main.rs
lazy_static! { static ref HEAP_STRING: Mutex<String> = Mutex::new(String::new()); } #[no_mangle] pub extern "C" fn wasm_string_to_js() -> *const c_char { let s: String = "string from rust".to_string(); let mut output = HEAP_STRING.lock().unwrap(); output.clear(); write!(output, "{}\0", s).unwrap(); output.as_ptr() as *const c_char }
配列の受け渡し
配列(js->rust)
配列の受け渡しをする時もメモリ管理は重要です。
JavaScriptの方で配列用のメモリを確保し、Rust側でその値を*f32として受け取ります。
JavaScript側で普通にnew FloatArray(5)みたいな感じで配列を作っちゃうと動きません。
src/main.js
// array: js -> rust const wasm_array_to_rust = Module.cwrap('wasm_array_to_rust', null, ['number', 'number']); var len = 5; var bufsize = len * 4; var bufptr = Module._malloc(bufsize); Module._memset(bufptr, 0, bufsize) var buf = new Float32Array(Module.HEAPF32.buffer, bufptr, len); for (var i = 0; i < len;i ++){ buf[i] = 1.1 * i; } wasm_array_to_rust(len, buf.byteOffset); Module._free(bufptr);
src/main.rs
#[no_mangle] pub extern "C" fn wasm_array_to_rust(_len: i32, ptr: *const f32) { let len = _len as usize; let slice: &[f32] = unsafe { std::slice::from_raw_parts(ptr, len) }; for n in slice { println!("{}", n); } }
配列(rust->js)
RustからJavaScriptに配列を渡すときも、配列自体はJavaScriptで確保して、Rust側で値を埋めるようにします。
※Rustが1.16.0だとうまく行かなかったので、動かないときはRustのバージョンを上げるとよいかもです。
src/main.js
// array: rust -> js const wasm_array_to_js = Module.cwrap('wasm_array_to_js', null, ['number', 'number']); var len = 6; var bufsize = len * 4; var bufptr = Module._malloc(bufsize); Module._memset(bufptr, 0, bufsize) var buf = new Float32Array(Module.HEAPF32.buffer, bufptr, len); wasm_array_to_js(len, buf.byteOffset); document.getElementById('array').innerText = buf; Module._free(bufptr);
src/main.rs
#[no_mangle] pub extern "C" fn wasm_array_to_js(_len: i32, ptr: *mut f32) { let len = _len as usize; let mut v: Vec<f32> = vec![0.5; len]; v[3] = 99.3; let mut res: &mut [f32] = unsafe { std::slice::from_raw_parts_mut(ptr, len) }; res.clone_from_slice(&v.as_slice()) }
感想
就活生にWebAssemblyについて質問されたが、うまく答えられなかったのでWebAssembly勉強したい。- Rust×WebAssemblyで遊ぼうと思ったが、ここでかなり詰まってしまった。
- せっかくJavaScriptとRust使っているのにCみたいにメモリ管理するの辛い。
- ここを乗り切れば平和な世界が訪れる?
- JavaScriptもRustも超初心者なので何か間違ってる気がする
【Tensorflow】TFRecordファイルでshuffle_batchしたときの偏り調査
Tensorflowでは色々な形式のデータのRead/Writeに対応しています。 これらの入力形式の中で最もスタンダードなのがTFRecord形式です。(とドキュメントに書いてました)
TFRecord形式のファイルには、1つのファイルに複数のデータを格納できるので、 毎日大量に生成されるようなデータを扱う場合は、日毎にデータを作ればとてもファイルの整理がしやすそうです。
一方で、Tensorflowにはミニバッチを使った学習を簡単に行うための、tf.train.shuffle_batch関数が用意されています。
これは、複数の入力ファイル内のデータをshuffleしてミニバッチにしてくれる便利関数で、
大量データを扱うことを前提にした実装をするため、擬似的にshuffleしたバッチを作ります。
この「擬似的」というのが曲者で、 うっかり正例・負例を一つのファイルにそれぞれまとめて、 サンプルコード通りのパラメータでshuffle_batchを使ったりすると、 バッチ内が全部ラベルが同じであるミニバッチができてしまったりします。 (Reading data | TensorFlowをちゃんと読めば分かる話なのですが…)
今回は、TFRecordファイルでshuffle_batchを使う場合に、どのようにデータを保存すべきか、パラメータはどう選べばよいかを調査しました。
結論としては、以下の2点がわかりました。
- shuffle_batchを使いたいときは、 1つのTFRecordにパラメータcapacityより十分少ない数のデータしか入れてはいけない。
- バッチ作成のパフォーマンスを上げるときは、
num_threadsパラメータを1以上にするか、shuffle_batch_joinを使う。
では、以下に詳細を述べます。
事前知識
TFRecord形式
TFRecordはTensorflowのstandardなファイル形式で、中身はProtocol Bufferっぽいです。 1ファイルに、等形式の異なる値で構成されるデータ(int, floatの組等)を1ファイルに複数書き込むことができます。
公式ドキュメント: https://www.tensorflow.org/versions/r0.12/api_docs/python/python_io.html#tfrecords-format-details
tf.train.shuffle_batch
Tensorflowでshuffleしたミニバッチを使いたいときに利用する関数です。
公式ドキュメント: https://www.tensorflow.org/versions/r0.12/api_docs/python/io_ops.html#shuffle_batch
先に述べたとおりshuffleと書いているので、よしなに入力ファイルをshuffleしてくれような気がしますが、 正確なshuffleではなく(大量データを想定して)Queueをつかった擬似的なshuffleでミニバッチを作ります。
その為、入力データの1ファイルに複数データが入っている場合は、 パラメータを適切な値にしなければ、ミニバッチに含まれるデータに偏りが生まれます。
tf.train.shuffle_batchの偏り検証
使用したスクリプト
TFRecordの作成
https://github.com/ykicisk/minibatch_TFRecord/blob/master/create_tfrecords.py
詳細は省略しますが、このスクリプトを動かすと、以下のように10個のTFRecordファイルができます。 それぞれには、5000個ずつデータが入っています。
今回はあとでミニバッチを作るときに、どのデータがどのファイルの何番目に入っていたかをわかりやすくするため、
データの中にfile_idx(ファイルが何番目), record_idx(何個目のデータ)、ランダムなnumpy.ndarray(2x4)を格納しています。
$ mkdir data $ ./create_tfrecords.py data wirte: data/file00.tfrecord wirte: data/file01.tfrecord wirte: data/file02.tfrecord wirte: data/file03.tfrecord wirte: data/file04.tfrecord wirte: data/file05.tfrecord wirte: data/file06.tfrecord wirte: data/file07.tfrecord wirte: data/file08.tfrecord wirte: data/file09.tfrecord $ tree data data ├── file00.tfrecord ├── file01.tfrecord ├── file02.tfrecord ├── file03.tfrecord ├── file04.tfrecord ├── file05.tfrecord ├── file06.tfrecord ├── file07.tfrecord ├── file08.tfrecord └── file09.tfrecord 0 directories, 10 files
TFRecordの偏りの可視化
https://github.com/ykicisk/minibatch_TFRecord/blob/master/visualize_mini_batch.py
上記のcreate_tfrecords.pyで作ったTFRecordファイルでミニバッチを作り、その偏りを可視化するスクリプトです。
ミニバッチを作るときのパラメータを引数で指定できます。
tf.train.shuffle_batchのパラメータ
詳細は後述しますが、とりあえずざっくりどんなものがあるかだけ先に並べておきます。
| パラメータ | ざっくりした説明 |
|---|---|
| batch_size | ミニバッチのサイズ |
| min_after_dequeue | Queue(後述のExampleQueue)からdequeueしたときにQueueに最低でも残るデータ数 |
| capacity | Queueのサイズ |
| num_threads | 入力Queue(後述のFilenameQueue)のenqueueするthread数 |
上記のスクリプトでは、パラメータcapacityについてはドキュメントに習いcapacity = min_after_dequeue + 3 * batch_sizeで固定、他のパラメータはスクリプトで指定します。
また、引数--joinで、shuffle_batchの代わりにshuffle_batch_join(後述)を使います。
この場合、引数--num_threadsで指定した数のTFRecordReaderを作成します。
動作例
# パラメータnum_threadsを指定して、shuffle_batch_joinを利用する # dataは入力ファイル、tb_logはTensorBoardのログファイルを書き出すパス $ ./visualize_mini_batch.py --num_threads 10 --join data tb_log

横軸がバッチのインデックス、縦軸がレコードのインデックス、色がファイルを表します。 散布図の一点が1データを表し、何番目のバッチでどのファイルの何番目のデータが出てきたかを示しています。(全データ点の5%のみ表示します)
上記の例では、バッチ前半では各ファイルの前半のデータがよく出てきて、バッチ後半で後半のデータが出てくることがわかります。 つまり偏っています。
幾つかパラメータを変えて検証
検証では、偏りにはあまり関係ないbatch_sizeを10に固定して、 他のパラメータを幾つか変えてみます。
(検証1)公式ドキュメントの例と同じパラメータ
Reading data | TensorFlowに書かれたパラメータを試します。
$ ./visualize_mini_batch.py --min_after_dequeue 10000 --num_threads 1 data tb_log_default

1ファイル内でのshuffleは若干後半のデータが後に出てくる傾向がありますが、それなりにできている気がします。
ただし、バッチをつくるときに同じファイルのデータしか出ていないことがわかります。 上記の結果の場合はfile01, file08のデータが前半のバッチによく出現して、file04, file09のデータは後半のバッチによく出現しています。
(検証2) shuffle_batch_joinを利用
Reading data | TensorFlowを読むと、
「ファイル間でもっとシャッフルしたいなら、tf.train.shuffle_batch_joinを使う(超意訳)」みたいなことが書いています。
とりあえず使ってみます。
$ ./visualize_mini_batch.py --min_after_dequeue 10000 --num_threads 10 --join data tb_log_t10_join
今度はファイル間のシャッフルはいい感じになっていますが、 バッチ前半でファイル前半データが、バッチ後半でファイル後半のデータが出るようになりました。
検証3| num_threadsを利用
公式ドキュメントをさらに読むと「
他にはtf.train.shuffle_batchでnum_threadsパラメータを1より大きくする手もある(超意訳)」
みたいなことが書いています。
とりあえず使ってみます。
$ ./visualize_mini_batch.py --min_after_dequeue 10000 --num_threads 10 data tb_log_t10

一見ではデフォルトパラメータと何も変わっていない様に見えます。
考察
shuffle_batchの挙動
Reading data | TensorFlowとプログラムの挙動を見る限り、 shuffle_batchは、以下のように動いているようです。
- ファイル単位でshuffleして、Filename Queueにenqueueする。
- Filename Queueからファイルを1つずつReaderが読み込み、Readerが指定したDecoderをつかってデータをデコードする。
- Readerはデコードしたデータ、ExampleQueueにenqueueする。
- shuffle_batchは、ExampleQueueが一定数(min_after_dequeue + batch_size?)溜まったら、ExampleQueueをshuffleして上からbatch_size個を出力する
コードではこんな感じになります。
# filenamesから、shuffle済みfilename_queueを作成 filenames = ["fileA", "fileB", "fileC"] filename_queue = tf.train.string_input_producer(filepaths, shuffle=True) # shuffle済みfilename_queueから、ファイルを1つずつ読み込むReaderを作成する reader = tf.TFRecordReader() _, selialized_data = reader.read(file_queue) # decoder data_def = {"key": tf.FixedLenFeature([2, 4], tf.float32)} # データ形式を指定 example = tf.parse_single_example(selialized_data, features=data_def) # パラメータを指定してバッチ作成 data_batch = tf.train.shuffle_batch( example, batch_size=batch_size, capacity=capacity, min_after_dequeue=min_after_dequeue, num_threads=num_threads, allow_smaller_final_batch=True )
何故偏ってしまったか?
Reading data | TensorFlowのGIFを使って説明します。
shuffle_batchは入力された全データではなく、ExampleQueueをshuffleします。 shuffle_batchの中身が偏っていたのは、そもそもExampleQueueが偏っていたのが原因です。
今回は1ファイルに5000個のファイルが入っていて、
ExampleQueueのサイズcapacityが min_after_dequeue + 3 * batch_size = 10000 + 30 = 10030でした。
この場合、ReaderがFilenameQueueから3つ目のファイルを読み込み始めたあたりでExampleQueueが一杯になり、 shuffle_batchがほぼ2つ目のファイルのデータしか入っていないExampleQueueをshuffleしてミニバッチを作る→一部のファイルのデータしかバッチに含まれない、となっていたと思われます。
(再掲)
shuffle_batch_joinの挙動
shuffle_batch_joinでは、先に述べた「Filename Queueからファイルを1つずつReaderが読み込む」というところが、 並列化されて複数のReaderで複数のファイルを同時に読み込んでExampleQueueにデータをenqueueします。
ただし、全Readerがデータの1/5程度(全体では、5000 * 10 / 5 = 10000 ≒ capacity) を読み込んだ時点で
ExampleQueueが一杯になってしまうため、最初の方のバッチはファイル前半のデータで占められてしまっっていたと思われます。
(再掲)
num_threadsを1より大きくした場合の挙動
Reading data | TensorFlowを良く読むと、 「num_threadsを1より大きくすると、1つのファイルをReaderが同時に読むようになって早くなるよ」的なことが書いてあります。 How toのGIF的にいえば、Reader1, Reader2というのがまさにこれに当たります。
複数スレッドでReaderが動いたとしても、1つのファイルからデータを読み込んでいるので、ExampleQueue内の偏りは解消できません。 そのため、データの偏りを可視化したときは、デフォルトパラメータと同じような結果になったと思われます。
では、num_threadsをいつ使えばよいかというと、ファイルのロードやdecodeに時間がかかる場合に、shuffle_batchが学習のボトルネックになるのを防ぐ目的で使えそうです。 この様子はReading data | TensorFlowにある通り、Tensorboardをみればわかります。
shuffle_batchをつかうと、TensorBoardのEVENTSにqueueというグラフが追加されます。
$ tensorboard --logdir=tb_log_default

ドキュメントが見つからなかったので詳細は良くわかりませんが、
どうやらqueue/shuffle_batch/fraction_over_10000_of_30_fullというのが、ExampleQueueがいっぱいになっている割合みたいなものを表しているようです。
この場合は、全ステップで1より小さいので、ExampleQueueがいっぱいになっているタイミングが無い=Readerがファイルをロード・デコードする部分がボトルネックになっている、 ということがわかります。
※ queue/input_producer/fraction_of_32_fullというのは、FilenameQueueの方を表しているみたいです。
バッチを読み込んでいくに連れて1つずつファイルが読み込まれていることを表していると思われます。縦軸はよくわかりません。
これに対して、num_threadsを10にした場合は、これが常に1になっているので、 Readerの読み込みが十分早くボトルネックが解消されていることがわかります。
$ tensorboard --logdir=tb_log_t10

ちなみに、shuffle_batch_joinを使ったときも、Readerが複数あるので同様にファイルのロード・デコードが早くなっています。
$ tensorboard --logdir=tb_log_t10_join

num_threadsを指定した場合は同ファイルのデータが同じバッチに入りやすくなり、shuffle_batch_joinを使用した場合は同ファイルの前半・後半のデータが同バッチに入りにくくなります。
この性質に注意してどちらを使うべきかを選べばよいかと思います。
結局どうすればよかったか?
今回は、ExampleQueueのcapacityが小さすぎたのが問題なので、
一番簡単な方法はパラメータcapacityを大きくしてやれば良いです。
# 全データが入るサイズまでcapacityを大きくする $ ./visualize_mini_batch.py --min_after_dequeue 500000 --num_threads 1 data tb_log_m500000

ただし、これは全入力データを一旦メモリに載せるという話なので、大量データを使う場合には使えません。
他の解決方法としては、1つのTFRecordファイルに入れるデータの量を減らすという方法があります。 そもそもTFRecordで複数データをまとめるとファイルの管理が楽そうだというモチベーションでTFRecordを使い始めましたが、運用上の問題が無い限り複数データを1ファイルに入れないほうが良さそうです。
やむを得ず1ファイルに複数データを入れる場合でも、1つのTFRecordにはcapacityより十分少ない数のデータしか入れてはいけません。
まとめ
今回は、Tensorflowのshuffle_batchを使うときのパラメータと、それを変化させたときのバッチの偏りについて調査しました。
その結果、以下の2つがわかりました。
- shuffle_batchを使いたいときは、 1つのTFRecordには
capacityより十分少ない数のデータしか入れてはいけない。 - バッチ作成のパフォーマンスを上げるときは、
num_threadsパラメータを1以上にするか、shuffle_batch_joinを使う。
参考にしたページ
開発合宿で作ったアプリをリリース && 地名から緯度経度を取得するAPIの比較
5月の連休中に、友人と温泉旅館でswift開発合宿をしました。
そこで作ったアプリを少しずつ肉付けして、本日ようやくAppleの審査を通過してリリースできました。
作ったアプリ: どこでも展望台

アプリ説明用画像

どこでも展望台について
アプリ「どこでも展望台」は、画像を見てもらえばだいたいわかると思いますが、 登録したランドマークの方角と距離をARで表示するアプリです。
主に展望台あっちに富士山が見えるはず・・・みたいな時に利用することを想定しています。
無料なのでぜひ使ってみてくださいね!
このアプリでは、サイドメニューから地名を入力してランドマークを登録するのですが、 この地名→緯度経度を取得するところで結構右往左往してしまいました。
ということで今回は、どこでも展望台を開発する家庭で得られた 地名から緯度経度を取得するAPIの比較について紹介します。
地名からの緯度経度情報を取得方法の検討
結論から先にいうと、Google Maps APIのPlaces API Web Serviceを使うのが一番よいです。
以下、検討の詳細です。
ジオコーディングと逆ジオコーディング
「地名 緯度経度 取得」みたいなクエリでググると、 ジオコーディングと逆ジオコーディングなるものがあることがわかりました。
ざっくりいうと
- ジオコーディング: 住所→緯度経度の変換
- 逆ジオコーディング: 緯度経度→住所の変換
のことです。
今回は、ジオコーディングっぽいですが、住所ではなく地名を直接緯度経度に変換することが目的です。
今回扱う地名→緯度経度の変換の名称は結局わからないままでした。
地名→緯度経度の変換方法
今回は、swiftでiosアプリを作ることを前提としています。また、お金は出したくないです。
この制約の下で使える地名→緯度経度の変換方法について以下の4つを検討しました。
※ 順番は検討した順番
比較した内容
検討では、以下の観点について比較を行いました。
※ 何れも2016/06/09時点の比較です
また、性質の違いがわかりやすいクエリとして、「東京タワー」「富士山」「六本木一丁目駅」「ランドマークタワー」の結果も記載します。
(結果自体をのせるのはダメっぽいので成功・失敗についてのみ記載)
結果
概要
| 方法 | カバレッジ・精度 | APIの制限 | 備考 |
|---|---|---|---|
| Geocoding API | ○ | 5秒に1回以上のアクセスはNG | 1クエリに対して1Result。 レスポンスがやや遅い(3〜5秒) |
| CLGeocoder | ✕ | 制限はあるが具体的な数値は書いてない | - |
| YOLP コンテンツジオコーダAPI | ✕ | 1日50000回以下(実際は不明?) | - |
| Google Maps API | ○ | 1日100回。ただしクレカ登録で1日15000回までUP | クレカ登録ではお金は発生しない |
詳細
Geocoding API
- APIのトップに仕様・利用規約が書かれています
- 裏でGoogle Maps APIを叩いている?ので精度はかなり良いようです。
- 5秒に1回以上のアクセスは禁止しています。
地名→緯度経度の変換例
| クエリ | 成功 or 失敗 | 備考 |
|---|---|---|
| 東京タワー | ○ | - |
| 富士山 | ○ | - |
| 六本木一丁目駅 | ○ | - |
| ランドマークタワー | ○ | - |
CLGeocoder
- 純正のジオコーダ。基本iphone限定になってしまう。
- 精度はかなりイマイチな感じ。今後に期待。
- API制限についてはドキュメントに以下のように記載されています。
Geocoding requests are rate-limited for each app, so making too many requests in a short period of time may cause some of the requests to fail.
地名→緯度経度の変換例
| クエリ | 成功 or 失敗 | 備考 |
|---|---|---|
| 東京タワー | ○ | - |
| 富士山 | ○ | - |
| 六本木一丁目駅 | ✕ | 麻布十番一丁目がHIT |
| ランドマークタワー | ✕ | HITしない。 「横浜ランドマークタワー」ならHIT |
YOLP コンテンツジオコーダAPI
- 住所検索とランドマークの検索ができる
- YOLPの「ランドマーク」に定義されていないもの(山など)は取れない?
- 利用制限については、APIの合計で50000回 && API単体制限回数があるとのことですが、 コンテンツジオコーダ自体のAPI制限についての記載は見当たりませんでした。
| クエリ | 成功 or 失敗 | 備考 |
|---|---|---|
| 東京タワー | ○ | - |
| 富士山 | ✕ | 富士山駅がHIT |
| 六本木一丁目駅 | ✕ | 六本木駅がHIT。 |
| ランドマークタワー | ✕ | HITしない。 「横浜ランドマークタワー」だと横浜駅がHIT |
Google Maps API
- 安心と信頼のGoogle Map API
- 制限については、Google Maps APIとして24hあたり1000回ですが、 クレジットカードを登録して本人確認を行えば150000回まで増えます。
- ただし、テキスト検索(地名で検索)する場合にはAPI 10回分消費するので、実質1日15000回。
使用制限は、Google 周辺検索サービスと Google プレイス テキスト検索サービスとで共通ですが、テキスト検索サービスには 10 倍の乗数が適用されます。つまり、テキスト検索リクエスト 1 回で、リクエスト 10 回分の割り当て量を使用することになります。Google Maps API for Work の契約の一部として Google Places API を購入した場合、乗数は異なります。詳しくは、Google Maps API for Work のドキュメントをご覧ください。
| クエリ | 成功 or 失敗 | 備考 |
|---|---|---|
| 東京タワー | ○ | - |
| 富士山 | ○ | - |
| 六本木一丁目駅 | ○ | - |
| ランドマークタワー | ○ | - |
考察
地名から緯度経度情報が欲しい時、最低限の精度を満たすのは、Geocoding APIかGoogle Maps APIだと思います。
ただし、Geocoding APIは元データがGoogle Maps APIですし、 大量のAPI利用はできないので、普通にGoogle Maps APIを使っておけば良さそうです。
結論
地名から緯度経度情報がほしい時は、今のところGoogle Maps API一択で良いと思います。
何れの方法を使うにしても、必ず利用規約をよく読んで正しく使いましょう。
私の場合は、Google Maps APIに以下の制限があるのに後で気づいて実装やり直しが何回か発生してしまいました。。